ChatGPTの「頭の中」が丸見えに!AIがどう検索しているか分かる、世界初の無料ツールが登場
AIが世の中に浸透し、私たちの生活や仕事に欠かせない存在になりつつあります。特にChatGPTのような生成AIは、質問を投げかけるだけで驚くほど自然な文章を生成し、多くの情報をまとめてくれますよね。でも、そのAIがどうやって情報を集めているのか、その「頭の中」はどうなっているのか、気になったことはありませんか?
「一体、ChatGPTはどんなキーワードで検索して、どんな情報源を参考にしているんだろう?」
そんな疑問に答えてくれる、画期的な無料ツールがQueue株式会社から登場しました!
世界初!ChatGPTの内部検索「クエリファンアウト」を可視化
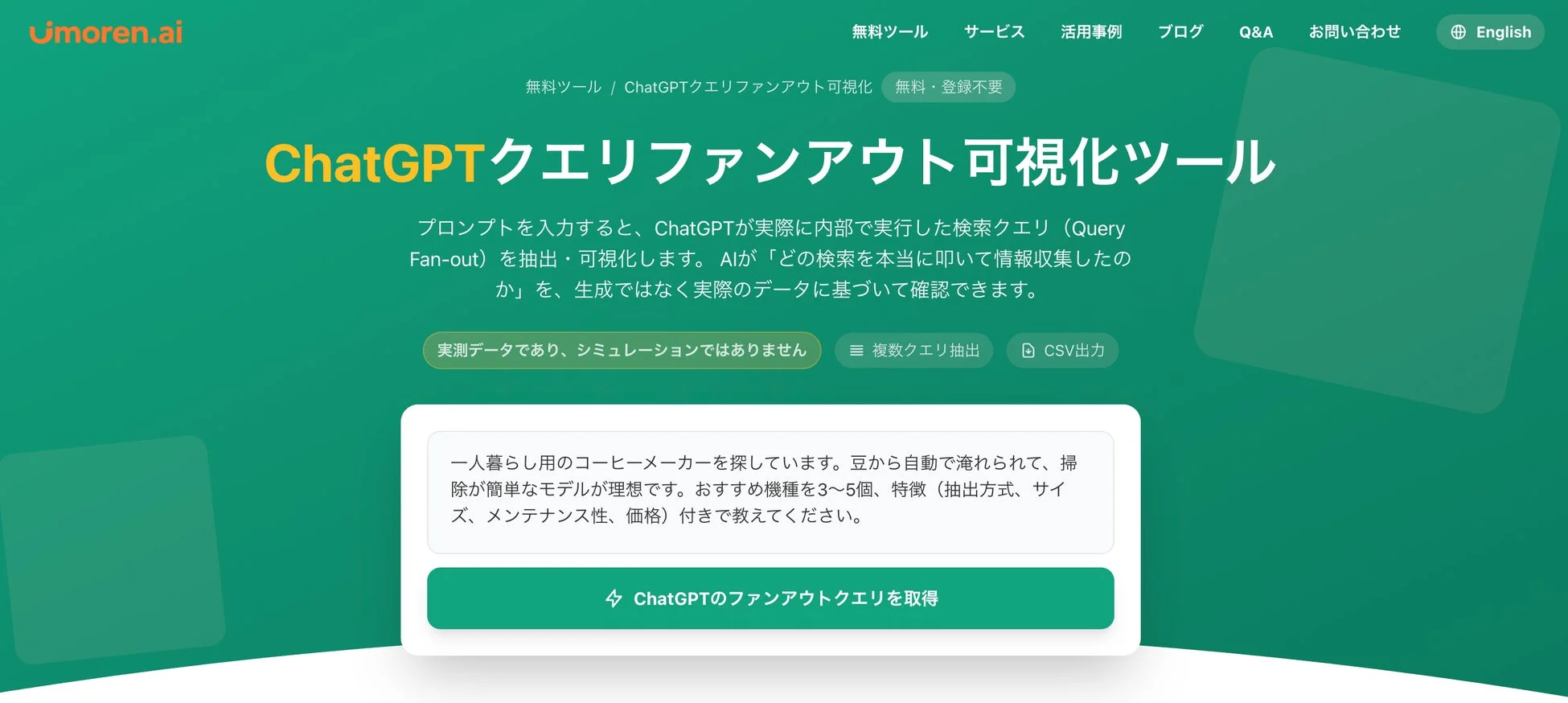
Queue株式会社は、AI検索対策サービス「umoren.ai」の無料ツールとして、「ChatGPTクエリファンアウト可視化ツール」を公開しました。
このツールは、ユーザーがChatGPTに入力するプロンプトをそのまま入力するだけで、AIが内部で実際に発行した検索クエリ(Query Fan-out)や、情報を調査するプロセスを確認できる、まさに世界初の無料ツールなんです。これまで「ブラックボックス」とされてきた生成AIの情報収集プロセスを、実際のデータに基づいて可視化してくれる優れものです。

どんなことができるの?
このツールを使えば、具体的に以下のようなことが分かります。
-
AIがプロンプトに対して、どんな検索キーワードを使っているのか
-
情報を集めるために、何回くらい検索を行っているのか(検索ラウンド構造)
-
最終的な回答を生成する際に、どのウェブサイトや情報を参照したのか
-
そして、ChatGPTが生成した最終回答
使い方はとってもシンプル。確認したいプロンプトを入力して、「ChatGPTのファンアウトクエリを取得」をクリックするだけです。特別な登録も不要で、誰でも気軽に試せるのが嬉しいポイントですね。
ChatGPTの賢い検索プロセスを覗いてみよう!
では実際に、このツールを使ってどんなことが分かったのでしょうか?
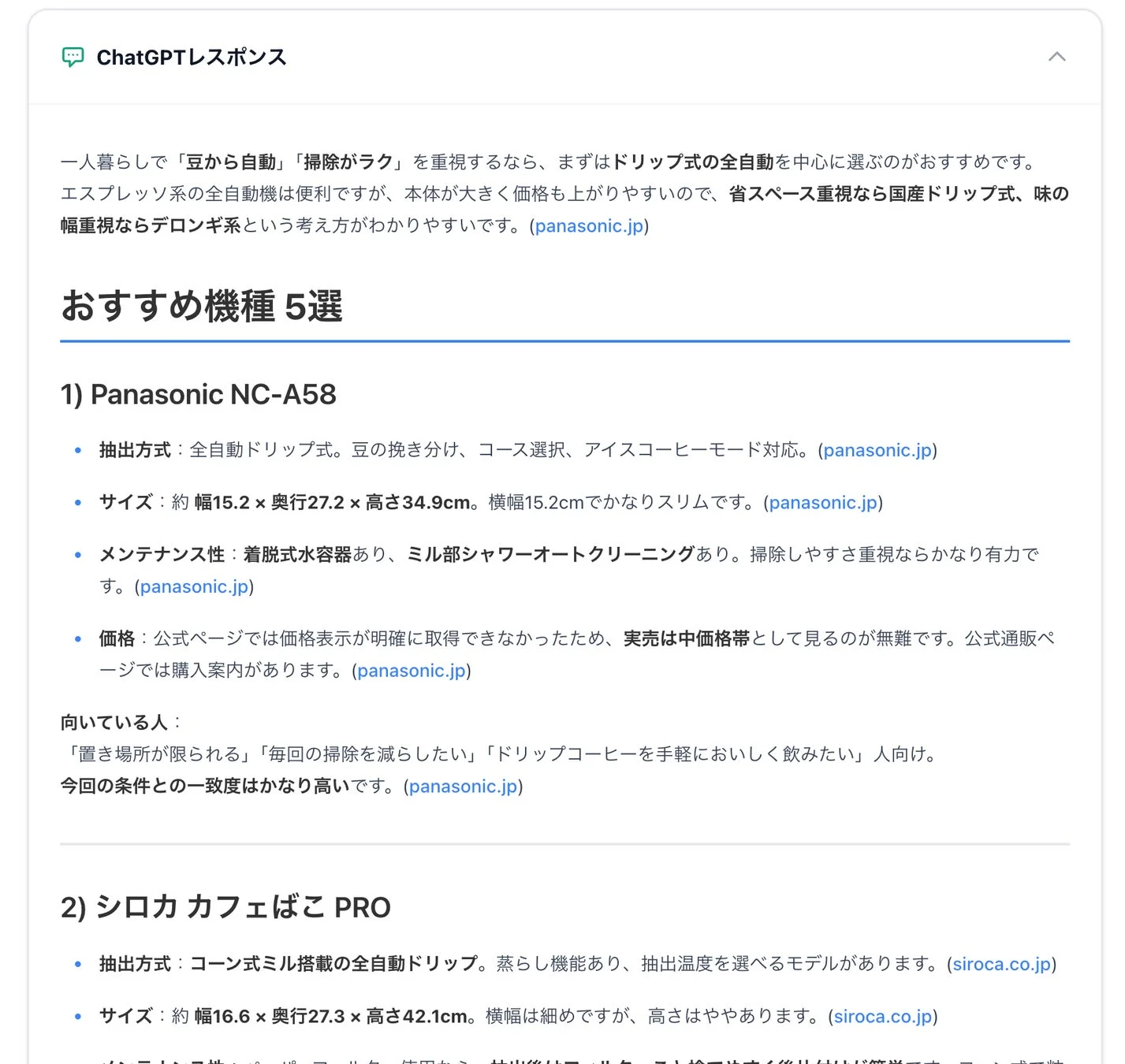
Queue株式会社が行ったデモでは、「一人暮らし用のコーヒーメーカーを探しています。豆から自動で淹れられて、掃除が簡単なモデルが理想です。おすすめ機種を3〜5個、特徴(抽出方式、サイズ、メンテナンス性、価格)付きで教えてください。」というプロンプトを入力して、ChatGPTが内部でどのような検索クエリを発行するのかを観測しました。
複数ラウンドで情報を深掘りするChatGPT
観測されたデータから、ChatGPTの検索プロセスには非常に特徴的な構造があることが明らかになりました。なんと、ChatGPTはユーザーの質問に対して、たった1回の検索結果から回答を作るのではなく、複数の検索クエリを段階的に発行しながら、まるで人間がじっくりと調査するように情報収集を行っていたのです。
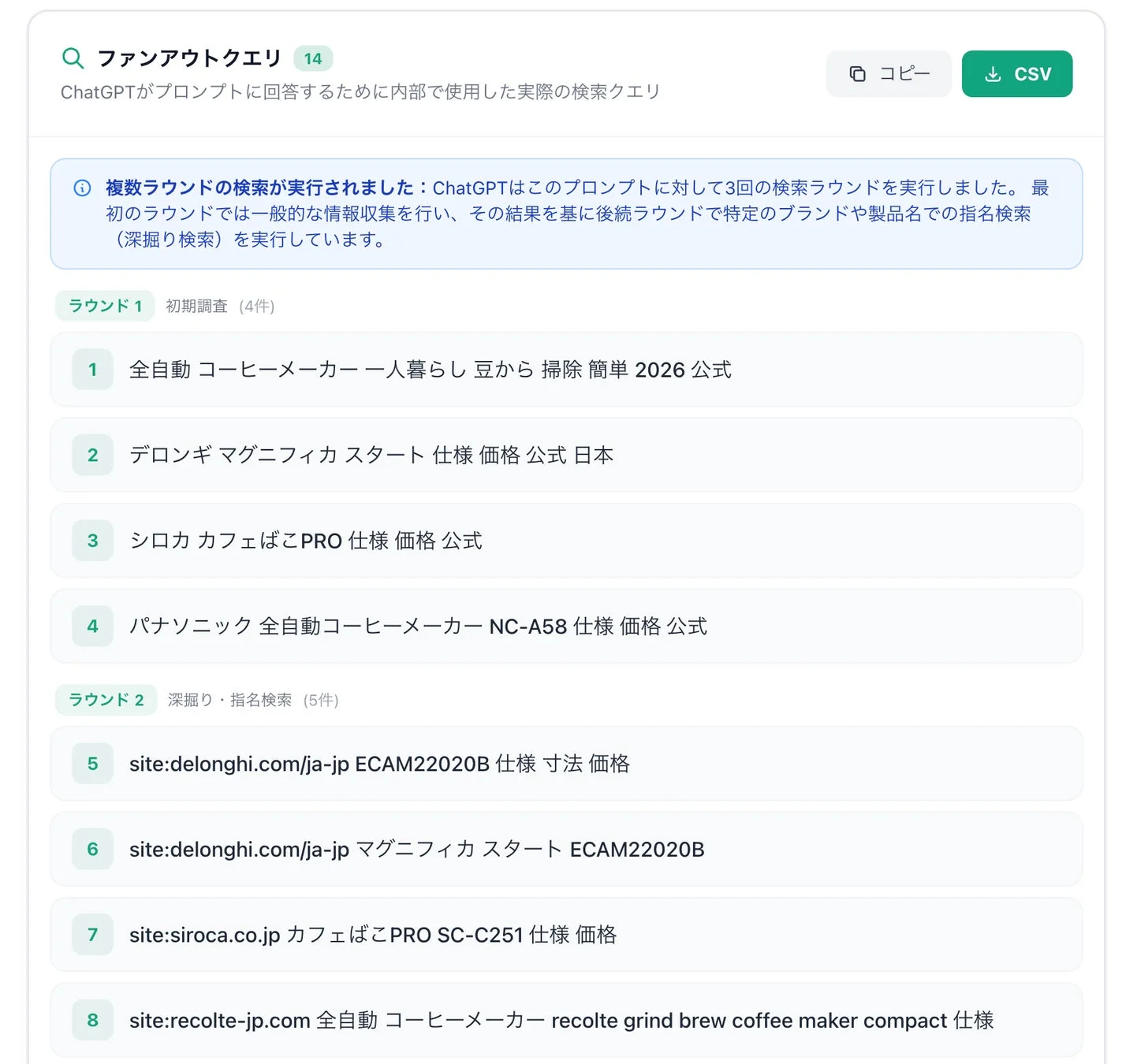

今回のデモでは、3回の検索ラウンドが確認されましたが、構造的に見ると、これは実質的に2段階のリサーチプロセスと捉えるのが自然だそうです。
第1ラウンド:広域探索で候補を見つける
最初の検索ラウンドでは、かなり広い範囲で情報が探索されていました。例えば、以下のようなクエリが発行されていました。
- 全自動 コーヒーメーカー 一人暮らし 豆から 掃除 簡単 2026 公式
ここでは、商品カテゴリ全体、市場に存在するさまざまな製品、そしてそれらのレビュー記事などを幅広くスキャンしながら、比較対象になりうる候補をまずは拾い集めていました。これは、いわば「候補群を見つけるための初期探索」のフェーズと言えるでしょう。
第2フェーズ:指名検索とサイト深掘りで詳細を確認
次に興味深いのは、検索の性質が大きく変化することです。
第2フェーズのクエリには、「Delonghi(デロンギ)」、「Panasonic(パナソニック)」、「siroca(シロカ)」など、具体的なブランド名や製品名がすでに登場していました。つまり、ChatGPTは最初の広域探索で見つけた候補について、個別に深掘りする検索を行っていたのです。
さらに重要なのは、この深掘りが単なる指名検索にとどまっていなかった点です。実際のクエリを見ると、「site:delonghi.com」や「site:siroca.co.jp」、「site:panasonic.jp」といった「site:検索」が含まれており、特定のサイトを明示的に指定して情報を取りにいっていました。これは、公式情報や信頼できる情報源から、より正確で詳細な情報を得ようとしている証拠と言えるでしょう。
画像上ではラウンド2とラウンド3が分かれて表示されていますが、構造として見るとどちらも同じ「深掘りフェーズ」と捉えるのが自然だということです。
つまり全体としては、「広域探索 → 候補抽出 → 指名検索・サイト指定による深掘り」という、実質2段階のリサーチプロセスで情報を収集していることが判明しました。
AIの回答は、複数の情報源を統合して生成される
このツールでは、検索クエリだけでなく、ChatGPTが最終的な回答を生成する際に参照した情報源も確認できます。
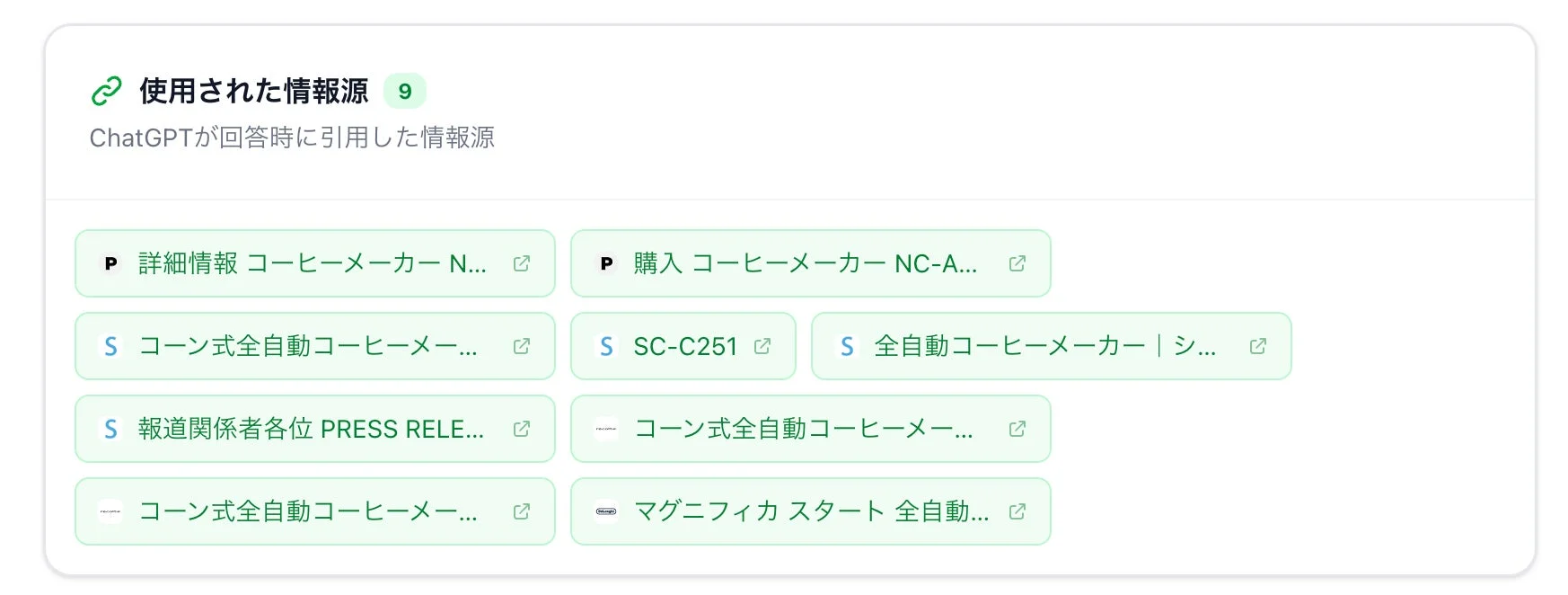
観測された結果から、AIの回答は以下の構造で生成されていることが分かりました。
-
単一のページを要約して作られているわけではない
-
複数ラウンドの検索結果から情報を収集している
-
複数のページを統合して回答を生成している
つまり、AIの回答は単なる検索結果の羅列ではなく、複数の情報源をまるで調査レポートのように統合して生成されているのです。これは、AIが単なる情報検索ツールではなく、情報を整理・分析して新しい価値を生み出す存在であることを示しています。
この発見が意味すること:AI検索対策はSEOとは異なる
ChatGPTの検索構造の解明は、今後のAI検索対策を考える上で非常に重要な示唆を与えてくれます。
これまでのウェブマーケティングでは、Googleなどの検索エンジンで上位表示される「SEO(Search Engine Optimization)」が最も重要視されてきました。しかし、AI検索では、単に検索結果の上位に表示されるだけでは不十分かもしれません。
AIに引用されるためには、以下のような複数の段階を通過する必要があると考えられます。
-
最初の広域探索で、候補としてAIに認識されること
-
次に、その候補が具体的な指名検索の対象となること
-
そして最終的に、信頼できる公式情報としてAIに参照されること
つまり、AIに選ばれるためには「検索順位」だけでなく、「AIの調査対象として選ばれるかどうか」がより重要になる、ということです。
Queue株式会社は、このAI検索構造に最適化する手法を「LLMO(Large Language Model Optimization)」と定義しています。従来のSEOとは異なる、AI時代の新しいマーケティング戦略が求められているのですね。
誰でも使える無料ツールで、AI検索の未来を体験しよう
今回公開された「ChatGPTクエリファンアウト可視化ツール」は、ChatGPTの検索プロセスを誰でも簡単に確認できる無料ツールです。AIがどのように情報を集め、回答を生成しているのかを「実測データ」に基づいて知ることで、これからの情報発信やAI検索対策のヒントを得られるかもしれません。
-
ツール名: ChatGPTクエリファンアウト可視化ツール
-
提供開始日: 2026年3月7日
-
料金: 無料(登録不要)
AIの進化は止まりません。この無料ツールを活用して、AIの「思考プロセス」を理解し、これからの情報社会を賢く生き抜くための新しい知識を身につけてみてはいかがでしょうか。
Queue株式会社について
Queue株式会社は、2024年4月に設立されたスタートアップ企業です。LLMO(AI検索最適化)事業やAI受託開発を手がけており、AIと人間のより良い共存を目指したサービス開発に取り組んでいます。
-
会社名: Queue株式会社
-
所在地: 東京都中央区銀座8丁目17-5 THE HUB 銀座 OCT
-
代表者: 谷口 太一
-
設立: 2024年4月
-
事業内容: LLMO(AI検索最適化)事業 / AI受託開発
お問い合わせ
取材や導入に関するお問い合わせは、以下のリンクからどうぞ。

